AI for Security
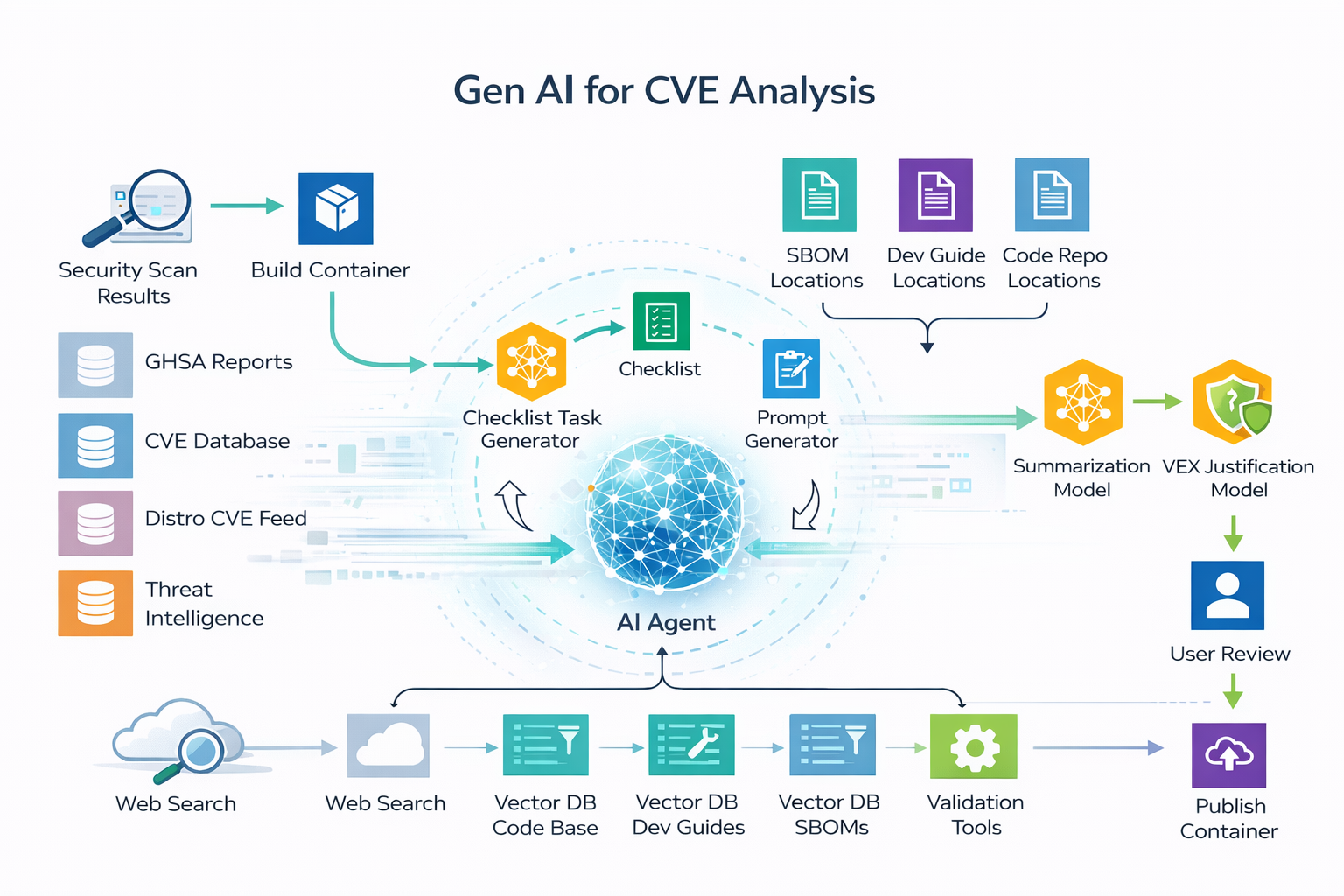
AI is changing the way security problems are discovered, analyzed, and monitored. Modern AI systems can help security analysts reason about source code, binaries, patches, logs, vulnerability reports, execution traces, and proof-of-concept exploits. Recent frontier cybersecurity efforts, such as Anthropic’s Claude Mythos Preview and Project Glasswing and its related technical blog post, suggest that AI is becoming an active participant in vulnerability discovery and security analysis, not merely a tool for summarizing documents. Related industry discussions, such as Forrester’s analysis of Project Glasswing, also highlight how AI-driven vulnerability discovery may reshape future security workflows.
This shift creates two closely related research questions. First, can AI help us find security problems in conventional computing systems, such as vulnerable code, suspicious logs, abnormal network behavior, misconfigured services, or unsafe system workflows? Second, as AI becomes part of the system itself, can we detect when AI-driven systems behave incorrectly, inefficiently, or unsafely? Examples include prompt injection, jailbreak attempts, poisoned retrieval results, unsafe tool calls, abnormal token usage, unintended data access, and suspicious agent-to-agent communication.
Our lab studies AI for Security as a way to diagnose security problems in both conventional computing systems and AI-driven systems. Rather than focusing only on traditional machine-learning-based detection, we are interested in AI systems that can reason across heterogeneous security evidence, interact with tools, monitor AI-agent workflows, and support human analysts in high-stakes security tasks. In short, we study how AI can help find when systems go wrong — and when AI itself starts going wrong.
Core Research Themes
Our lab explores AI for Security through the following research directions:
- AI-Assisted Vulnerability Analysis: Using LLMs and AI agents to analyze code, patches, bug reports, vulnerability descriptions, execution traces, and proof-of-concept exploits.
- Security Diagnosis for AI-Driven Systems: Detecting abnormal behavior in AI applications, including unsafe tool use, unexpected data access, excessive token usage, and suspicious workflow patterns.
- Prompt Injection and Jailbreak Detection: Studying how AI systems can identify malicious prompts, poisoned contexts, misleading retrieved documents, and attempts to manipulate AI-agent behavior.
- AI-Agent Workflow Monitoring: Analyzing logs, tool calls, memory access, retrieval results, MCP-style tool interactions, and agent-to-agent communication to detect security-relevant anomalies.
- AI Red Teaming and Blue Teaming: Studying how AI can support both offensive security analysis and defensive response in authorized and responsible settings.
- Reliability of AI-Based Security Analysis: Evaluating when AI security tools succeed, when they fail, and how misleading or incomplete evidence affects their conclusions.
Key Sub-Topics & Keywords
To give you an idea of potential topics you may be interested in, our research includes, but is not limited to:
- LLM-assisted vulnerability discovery and triage
- AI-based detection of prompt injection and jailbreak attempts
- Monitoring AI-agent tool use, memory access, and workflow behavior
- Detection of abnormal token usage and suspicious AI-system behavior
- Security analysis under poisoned or misleading knowledge
- AI-assisted incident analysis and security report generation
- Red-team and blue-team evaluation of AI security agents
Student Note: If you are interested in both AI and cybersecurity, this field may be a good fit for you. You will study how modern AI can help find vulnerabilities, analyze complex security evidence, and support security analysts. At the same time, you will learn how to detect when AI-driven systems themselves behave abnormally, insecurely, or inefficiently — and why such systems must be carefully evaluated, monitored, and controlled before they can be trusted in real-world security workflows.