Secure AI Agent Harness
AI agents are rapidly moving beyond simple question answering. They can now retrieve documents, call tools, access databases, write code, communicate with other agents, and make decisions across complex workflows. As these agents become more capable, they are also becoming part of the computing system itself. This raises an important question: How can we safely control AI agents that can observe, decide, act, and communicate?
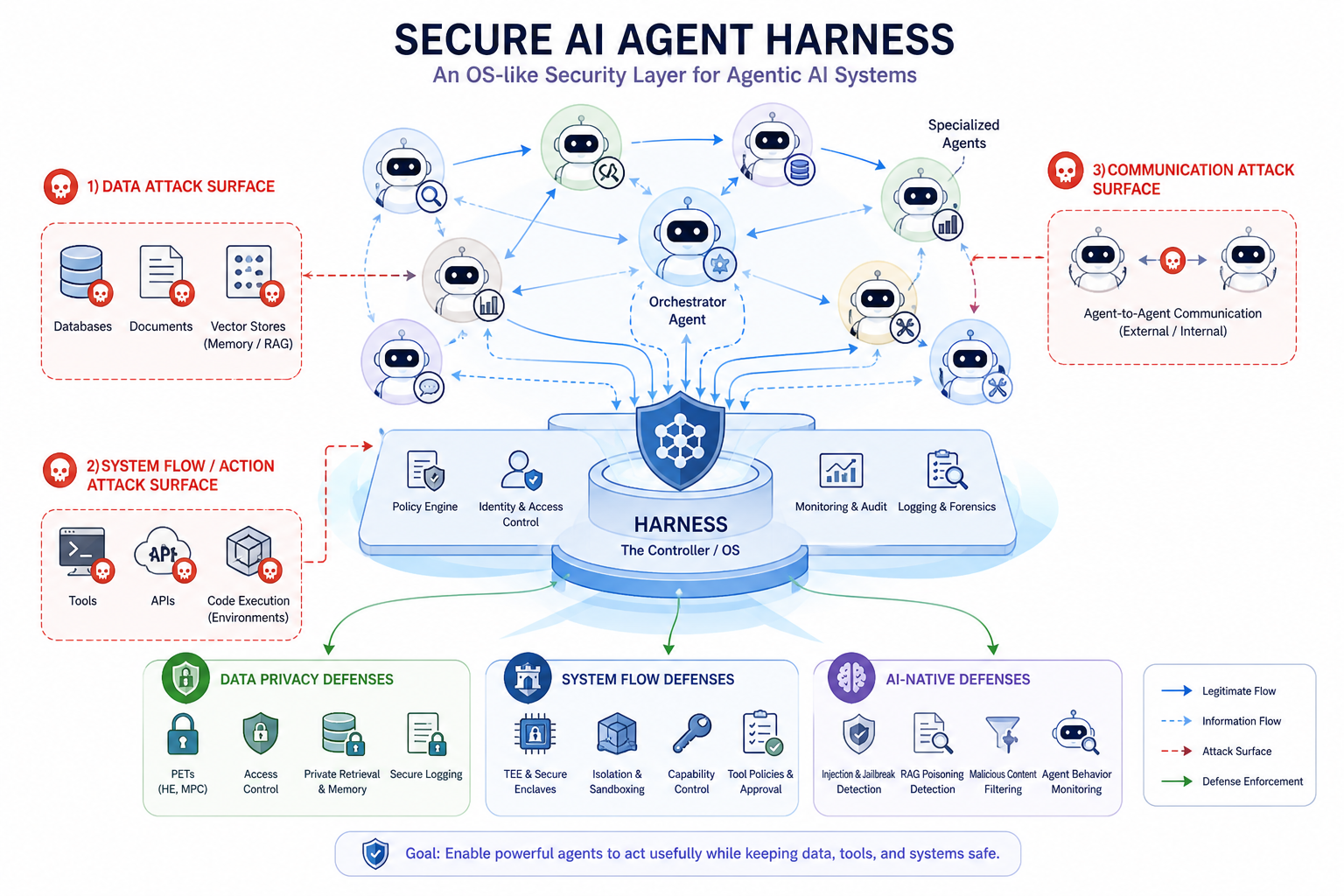
Our lab studies Secure AI Agent Harnesses: system-level security layers that manage and constrain AI-agent behavior. A useful analogy is to think of an AI agent as a new kind of CPU. The agent reasons and decides what to do next, while databases, documents, tools, APIs, memory, and other agents act like memory and I/O devices. In this analogy, the harness plays the role of an operating system: it mediates access, enforces permissions, isolates risky behavior, monitors execution, and records security-relevant events.
Without such a harness, AI agents may become unsafe system components. They may access sensitive data unnecessarily, follow malicious instructions hidden in retrieved documents, call dangerous tools, leak private context, consume excessive resources, or communicate insecurely with other agents. Therefore, securing AI-agent systems requires more than making the underlying model “safer.” We need a practical security architecture that controls the entire agent workflow.
Core Research Themes
Our lab explores Secure AI Agent Harnesses through three closely connected security tracks:
-
Data Privacy Layer: Protecting the sensitive data that AI agents observe, retrieve, store, and generate. This includes user prompts, documents, embeddings, memory, logs, database records, and intermediate reasoning artifacts. We study techniques such as Privacy-Enhancing Technologies (PETs), Homomorphic Encryption, Secure Multi-Party Computation, TEEs, access control, private retrieval, privacy-aware memory, and secure logging to reduce unnecessary data exposure in AI-agent workflows.
-
System Flow Security Layer: Controlling how AI agents interact with tools, files, APIs, databases, execution environments, and external services. This layer focuses on techniques such as Trusted Execution Environments, sandboxing, process isolation, containerization, capability-based access control, tool-use policies, workflow verification, audit logging, and human-in-the-loop approval. The goal is to ensure that AI agents can only perform authorized actions under controlled conditions.
-
AI-Native Security Layer: Defending against attacks that are specific to AI-agent systems. Examples include prompt injection, jailbreak attempts, RAG poisoning, malicious retrieved documents, poisoned memory, tool manipulation, unsafe agent-to-agent communication, and misleading security evidence. This layer studies how to detect, prevent, and recover from attacks that manipulate the agent’s reasoning process or decision-making context.
Together, these three tracks form an OS-like security architecture for AI agents. The harness should determine what the agent can see, which tools it can call, what data it can modify, how it communicates with other agents, when human approval is required, and how suspicious behavior should be logged, blocked, or escalated.
Key Sub-Topics & Keywords
To give you an idea of potential topics you may be interested in, our research includes, but is not limited to:
- OS-like runtime security and policy enforcement for AI agents
- Privacy-preserving retrieval, memory, logging, and tool use
- TEE, sandboxing, isolation, and capability control for agent workflows
- Prompt injection, jailbreaking, RAG poisoning, and malicious-context defense
- Monitoring, auditing, and human-in-the-loop control of AI-agent behavior
- Secure agent-to-agent communication and MCP-style tool interactions
Student Note: If you are interested in operating systems, systems security, AI agents, privacy, and real-world security problems, this field may be a good fit for you. You will study how AI agents interact with data, tools, memory, and other systems, and how to design a harness that keeps those interactions safe. In short, this research asks how we can build the “operating system” that future AI agents need before they can be trusted with important tasks.